helloworld를 2진수로 표현하는 방법은 무엇이 있을까?
0. ASCII
현재 컴퓨터에서는 일반적으로 ASCII코드를 사용하고 있다.
아스키코드는 7비트의 수를 각각 1개의 문자에 대응 시킨 것이다.

하지만 보통 1바이트로 8비트를 사용하기 때문에 아스키코드는 실제 문자를 담는 영역은 7비트임에도 불구하고 또 다른 7비트의 공간에 다른 문자들을 할당하여 (움라우트 모음 등) 총 8비트의 공간에 문자를 표현하고 있다.
아스키코드를 이용한다면
helloworld는 80비트의 데이터 공간을 필요하게 될 것이다.
1. 필요한 문자들만 순서대로 코딩
아스키코드를 사용하는 것 보다 효율적인 방법은 뭘까?
helloworld를 보면 h,e,l,o,w,r,d 총 7개의 문자들의 조합으로 이루어져있다.
따라서 3비트에 각 문자들을 할당하면 3*10 = 30비트의 데이터 공간만으로도 원하는 내용들을 전할 수 있다.
예시)
h : 000
e : 001
l : 010
...
d : 110
2. 허프만 코딩
그러나 helloworld의 문자열의 각각의 문자들을 빈도분석을 통하여 8비트 혹은 3비트의 고정된 길이가 아닌 가변적인 길이로 각각의 문자를 할당해준다면 전체 문자열의 데이터 공간이 줄어 들 수도 있다.
Symbol Weight Huffman Code
l 3 10
o 2 01
h 1 000
r 1 001
w 1 110
d 1 1110
e 1 1111
많이 나오는 문자에게 짧은 code를 할당하고, 적게 등장하는 문자에는 3비트보다 긴 code를 할당하는 것을 생각해볼 수 있을 것이다.
이 때의 의문점은 다음과 같은 것들이 있을 수 있다.
1. 1비트 짜리 0이나 1은 왜 사용하지 않는가?
2. 왜 3비트보다 긴 1110이나 1111같은 code를 사용하는가?
만약 0과 1을 code로 사용했다고 가정하자.
001 이라는 문자열이 있다.
이것을 0,1과 저 위에 있는 표들로 부터 해석해보자.
문자열을 해석할 때에는 앞에서 부터 해석한다고 가정한다.
0,1이 존재한다면 001은 다음과 같이 해석될 수 있다.
001 = 0 0 1
001 = 0 01
001 = 001
정상적인 code라면 어떤 2진수의 데이터를 입력받아도 단 하나의 문자열에만 대응되어야 한다.
그런데 001이라는 입력을 받았을 경우 총 3가지로 해석될 여지가 존재한다.
이 경우 code는 제 기능을 하지 못하고 있는 것이다.
따라서 0과 1같은 code는 존재하지 않는다.
그리고 앞선 코딩 방식의 길이인 3비트보다도 긴 1110과 1111같은 4비트 짜리 code들이 있는 이유는,
적게 등장하는 문자들의 코드의 길이를 길게 하는 손해를 감수하면서도 자주 등장하는 심볼들의 코드의 길이를 짧게 하는 것이 더욱 전체 데이터의 크기를 줄이는 데에 영향을 주기 때문이다.
helloworld를 위에서 분석하여 제시한 코드표에 따라 변환해보자.
Symbol Weight Huffman Code
l 3 10
o 2 01
h 1 000
r 1 001
w 1 110
d 1 1110
e 1 1111
000 1111 10 10 01 110 01 001 10 1110
000111110100111001001101110
총 길이는 27비트이다.
기존의 30비트보다 3비트나 줄어든 결과이다.
'겨우 3비트 가지고? ㅁㅈㅎ'할 수도 있겠지만,
90%의 압축률을 보이면 1테라 짜리 데이터를 압축한다면 100기가는 절약할 수 있다는 뜻이다.
그리고 또한 지금의 경우에는 문자열의 길이가 충분히 길지 않아서 효율이 낮지만 문자열이 길어지고 각 문자들의 등장 빈도가 변화스러운 분포를 보일수록 더욱 효율이 높아진다.
3. 허프만 코딩 알고리즘
그렇다면 허프만 코드를 만드는 방법에 대해 알아보자.
허프만 코드는 단순히 빈도가 많은 문자들에 짧은 코드를 대응시키는 것으로 끝나지 않는다. (그렇다면 위의 경우에 l이나 o에 대해서는 0과 1을 대응 시켰어야 했다)
알고리즘이 어떻게 작동하는 지는 실제 예제를 보면서 보자.
1. 심볼들의 목록에서 등장 빈도가 가장 낮은 2개의 문자들을 하나로(하나의 트리로) 합친다.
2. 합쳐진 트리를 하나의 심볼로 취급하여 1의 과정을 반복한다.
3. 왼쪽으로 내려갈 때 0, 오른쪽으로 내려가면 1로 해서 코드를 만든다 (0,1 조합 대신 1,0 조합도 가능)
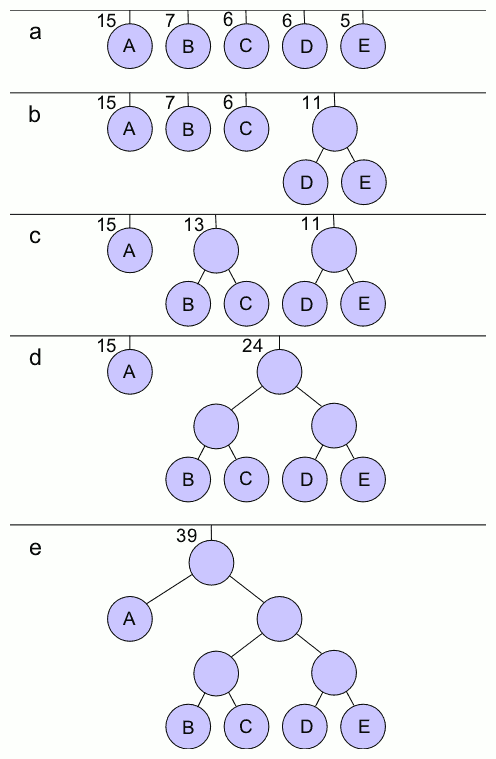
스텝a에서 가장 빈도가 적은 2놈들은 D와 E이다.
따라서 이것들을 하나의 트리로 묶는다. 묶은 트리의 빈도는 총 11이 된다.
A - (D&E) - B - C
15 - 11 - 7 - 6가 되었다.
스텝b에서는 가장 빈도가 낮은 (B,C)를 트리로 만든다.
A - (B&C) - (D&E)
15 - 13 - 11
스텝c에서는 (B&C)와 (D&E)를 트리로 만든다.
(B&C)&(D&E) - A
24 - 15
끝
최종 트리에서
a : 0
b : 100
c : 101
d : 110
e : 111
이 되었다.
4. 효율적인 예제
좀 더 긴 문장들로 예를 들어보자
One reason people lie is to achieve personal power. Achieving personal power is helpful for someone who pretends to be more confident than he really is. For example, one of my friends threw a party at his house last month. He asked me to come to his party and bring a date. However, I didn뭪 have a girlfriend. One of my other friends, who had a date to go to the party with, asked me about my date. I didn뭪 want to be embarrassed, so I claimed that I had a lot of work to do. I said I could easily find a date even better than his if I wanted to. I also told him that his date was ugly. I achieved power to help me feel confident; however, I embarrassed my friend and his date. Although this lie helped me at the time, since then it has made me look down on myself.
이를 허프만 코딩으로 변환하면 3240비트가 필요
기본 코딩으로 할 경우 4602비트 필요
약 70%의 압축률을 보인다.
3줄요약
1. 허프만 코딩을 이용하면 데이터를 압축할 수 있다














